HTML的三大概念:标签、元素以及属性标签:尖括号中的文本例:<head>……</head>标签通常成对出现元素:标签中的所有内容元素中可包含元素属性:标签的特殊标注等例:<ahref="http:\\www.…
问题: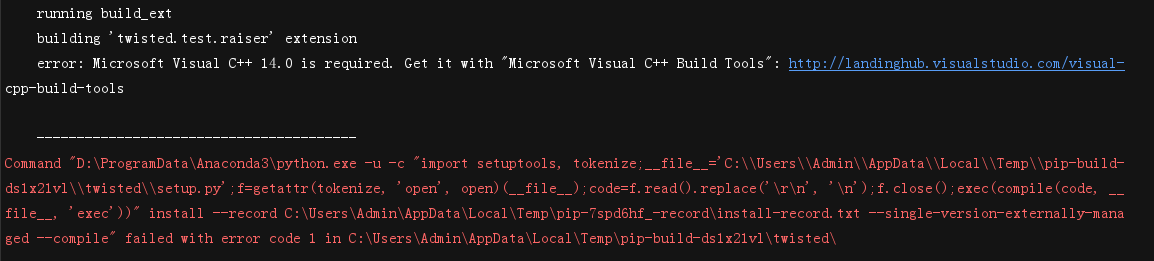解决办法(步骤):1.尝试将twisted包手动下…
安装依赖:yuminstalllibxslt-devellibffilibffi-develpython-develgccopensslopenssl-develsqlite-devel安装Python2.7或以上的版本(如果多版本共存则必…
原文学习链接:http://www.scrapyd.cn/doc/185.html一.标签属性值的提取href的值URL的提取:这是最常见的,我们要进入下一页、或是打开内容页……都少不了URL值,如下面这段HTML,我们来提取一下里面的UR…
在安装scrapy之前首先得确保你已经安装了python以及pip1,安装scrapypipinstallscrapy如果报错:CouldnotfindaversionthatsatisfiestherequirementTwisted&g…
scrapyd安装https://cuiqingcai.com/5445.htmlhttps://www.cnblogs.com/angdh/p/11886519.htmldocker环境安装scrapydhttps://www.cnblo…
一、创建工程#在命令行输入scrapystartprojectxxx#创建项目二、写item文件#写需要爬取的字段名称name=scrapy.Field()#例三、进入spiders写爬虫文件①直接写爬虫文件自己手动命名新建一个.py文件即…
目录前言安装Scrapy创建一个Scrapy项目创建一个爬虫运行爬虫结论前言Scrapy是一个基于Python的Web爬虫框架,可以快速方便地从互联网上获取数据并进行处理。它的设计思想是基于Twisted异步网络框架,可以同时处理多个请求,…
爬取目标:房天下全国租房信息网站(起始url:http://zu.fang.com/cities.aspx)爬取内容:城市;名字;出租方式;价格;户型;面积;地址;交通反反爬措施:设置随机user-agent、设置请求延时操作、1、开始创建…
安装的是Python3.7,装上依赖包和scrapy后运行爬虫命令出错1File"D:\Python37\lib\site-packages\scrapy\extensions\telnet.py",line12,in<module&…
最近因为一个作业需要完成CNKI爬虫,研究爬虫架构的时候发现了这个疑似移植于Python的著名开源爬虫框架Scrapy的ScrapySharp,然而在网上寻找之后只发现了这个F#的Demo,就使用原文中示例的网站写了这个C#版本的代码。PS…
Python分布式爬虫打造搜索引擎基于Scrapy、Redis、elasticsearch和django打造一个完整的搜索引擎网站https://github.com/mtianyan/ArticleSpider未来是什么时代?是…
创建Scrapy项目1#https://github.com/My-Sun-Shine/Python/tree/master/Python3/Scrapy_Learn/Scrapy_A2scrapystartprojectScrapy_A项…
想要执行parse能够在cmd看到parse函数的执行结果:解决方法:settings.py中设置ROBOTSTXT_OBEY=False案例:day96\day96\spiders\chouti.py#-*-coding:utf-8-*-…
